Collaborative Data Systems on Azure
Use of DevOps practices and principles for solution design, implementation, and operations of infrastructure to support business has been increasing in popularity over the years. Agile development enables teams to move fast and focus on value; we are empowered to chart our own path to deliver functionality that delights users, and adapt to changing requirements over time. Everything-as-code is standard, and being able to rapidly provision additional capacity or develop new features to meet demand is taken as a given.
These techniques and expections from software development are now front and centre in the modern data ecosystem. From small scale analytics projects to enterprise data mesh architecture, these systems will almost always benefit from modern tooling and agile development practices. Effective analytics teams need reliable mechanisms to manage and promote changes across environments, collaborate with others, and ensure reliability of these changes before they get to production. Further, these mechanisms must account for the entire analytics lifecycle - the infrastructure deployment and management (i.e. compute, storage, networking), as well as the analytics artefacts themselves (i.e. data pipelines, dashboards, models) that are developed on top of the platform.
A data system without processes to manage the data artefacts within are likely to cost more to run, have reduced impact, and higher levels of technical debt.
In this post, I will look at what makes data systems different when it comes to agile development, review two patterns for version control with databases and discuss the benefits and considerations of both approaches, and highlight how other components of the data platform can also integrate with an overall delivery pipeline to manage data artefacts.
What makes DevOps with Data different? #
There is one subtle difference in a data system - that of state management. Application development does not typically have this problem as new versions or features simply supersede the old. You don't want to lose data when deploying changes, so ensuring this process is managed reliably is critical. In order to ensure the data remains in place and usable, the processes that promote changes to your data infrastucture need to take the existing state of the system into account. There are common two approches to managing this process: migration-based deployments and state-based deployments.
Migration-based deployment #
At a high level, migration-based deployments capture a “starting point” implementation of a database script, which represents the initial state. Changes and additions are then developed from this point as incremental migration scripts, which are checked into version control and applied to the database. The state of the database can be rebuilt by re-running the database initialization script, then all subsequent migration scripts in sequence on a new instance.
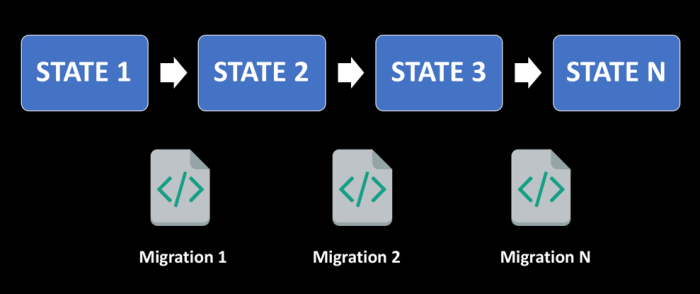
Migration-based deployment: changes are managed and deployed to the live database by applying a series of "migration scripts" on the system
State-based deployment #
A state-based deployment approach instead stores all database objects in source control as .sql files. New objects and updates to existing objects and are developed and added to these files in the repository, and tools are used to compare updated models to production databases to generate scripts to update the model in line with these changes. The scripts that are generated are similar to those that a developer would author in the migration-based deployment approach.
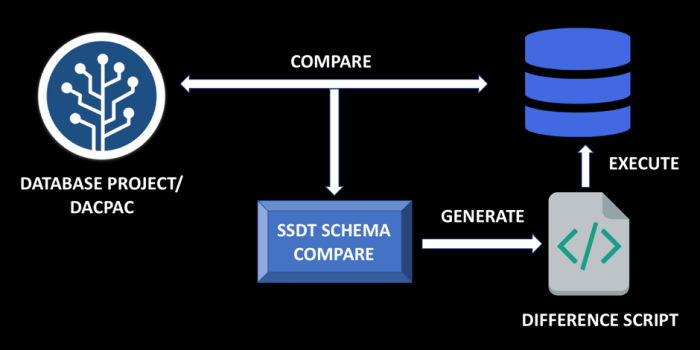
State-based deployment: Tooling is used to compare as-is and to-be state of the database - tooling like SQL Server Data Tools then generates a script to update the target database to the same state as the project model
Which is right for me? #
There is a case to be made for both approaches, and you need to consider the level of control you require over the changes you are making to your database.
I have a preference for state-based deployments as this approach relies on tools to generate the update scripts, leaving developers to focus on the changes that need to be made and hand off responsibility for the underlying state changes to the tooling. The state based deployment also reduces the barrier to entry as the repository itself is the control point for the state of the system, so updating objects in the database is similar to adding new functionality in a software project, which developers are likely to be more familiar with.
Migration based deployment does devolve full control over the changes that are made to developers, which may be preferable in some circumstances.
You might consider a hybrid approach too - state-based deployment tooling has the concept of pre and post deployment script steps, and these can be used to make manual changes to a deployment after the generated scripts have been created and executed in the database.
For further thoughts on the trade-offs between the two approaches, see this blog post from Samir Behara.
How can I start applying these processes to my Data System in Azure? #
If you opt for a state based approach to development, Azure SQL DB and Azure Synapse both have support for SQL Server Data Tools (SSDT). SSDT is free, and available as part of Visual Studio Community 2019. As part of the management of the analytics artefacts in your data system, you will also need to consider how you manage changes to data pipelines and dashboards. The support for this in Azure Data Factory is very comprehensive - the most recent update to this in February of this year has added support for the validation and publish of artefacts as part of your CI pipeline, meaning you can then manage the remaining deployment process in your pipelines. Automated deployment of artefacts in PowerBI takes a slightly different approach and use of version control is currently limited to use with OneDrive (i.e. not git) - you can read about deployment pipelines here.
NB: The "Database Projects" functionality in SSDT is also available in Azure Data Studio.
Further reading on this topic #
- Evolutionary Database Design | martinfowler.com
- Why You Should Use a SSDT Database Project For Your Data Warehouse | sqlchick.com
- DevOps for databases: “DataOps” | jamesserra.com
Conclusion #
We have looked at different approaches you can consider when adopting DevOps processes in your data system. I have focused on approaches to manage data artefacts in the database, and shared some further content and patterns to extend this process to manage lifecycle of the analytics artefact including the data pipelines and dashboard/reports.
Over the next few weeks I am going to write up some further information on this pattern, covering how you can get started with SQL Server Data Tools and Azure Synapse, and a deeper look at the SSDT Database Project. If you're looking for a hands on example, my Modern Data Warehouse with Terraform example I created earlier in the year to demonstrate how these systems can be managed and maintained should serve as a good starting point!
Please message me on Bluesky if this has been helpful, or useless, or if you have any questions or comments!