SQL Server Data Tools - A deeper look
In my last blog, I introduced the importance of leveraging DevOps practices and principles for your infrastructure and analytics artefacts, as well as discussing two possible approaches for managing changes to a database as part of this process, and some tooling that you can use to bring this theory into practice.
In this blog, I will dive deeper into the database project itself – what it is, how to manage it, and give a little more context so you know what to expect as you get started yourself.
All screenshots have been captured from Visual Studio 2019 Community Edition, which is currently my preferred tool for working with SSDT, however the same tools are now available as part of Azure Data Studio!
Database projects #
Database projects are composed of the .sql files that make up the data model in your system, and several configuration files that SQL Server Data Tools (SSDT) uses to manage, control, and apply changes to your database. When starting a new project you have two options: you can create a new empty database project, or import a database schema from an existing database, .sql script file or a Data-tier application (.dacpac).
As the focus of this blog is on SSDT project files, I have created a new “SQL Server Database Project” by following the “New Project” wizard in Visual Studio.
After instantiating a blank project, your solution will look like this:
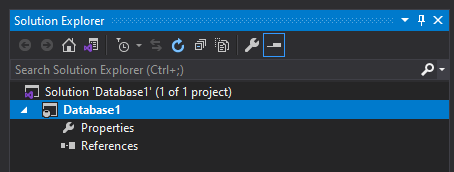
If you switch to the Folder view or look at this new directory in Windows Explorer, you’ll see these files:
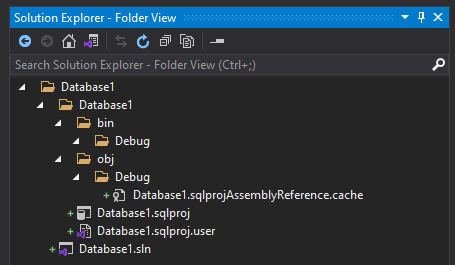
Let’s dig into each of these files – what are they for and how should you manage them? Working from the bottom up:
.sln #
The .sln file maintains the state information for the project. It is text based (you can open it in a text editor of your choice and take a look), and contains data that the environment and IDE uses to find a load parameters and packages that are required to work with items in the project. It is designed to be shared with all developers who interact with the repository. For an in depth look at .sln files, check the documentation
✅ Store .sln in version control
.sqlproj and .sqlproj.user #
The proj files contain the properties for your project and is used by Visual Studio’s “Build” action to tell it what to build. The main difference is the .sqlproj contains properties that are specific to the project (e.g. which .sql files in the project should be included when creating the data model), and the .sqlproj.user file contains your specific user options for the project. As you work with your project to add and change database objects, you will see this file get updated. For more info, see this page in the documentation
✅ Store .sqlproj in version control
❌ Do not store .sqlproj.user in version control
sqlprojAssemblyReference.cache #
.cache files in a Visual Studio project are used to track the work that previous build processes have done to speed up subsequent builds in the local environment. Because these are specific to the local environment, the .cache files should not be checked in to version control. This is also reflected in the boilerplate .gitignore file.
❌ Do not store .cache in version control
Working with SSDT – development best practice #
Set the target platform #
Make sure this is set correctly –Visual Studio uses this to automatically detecting any error in your code and to build a compatible DACPAC for the target data store. Go into the project settings by double clicking on “Properties”, to make sure the correct target platform is set.
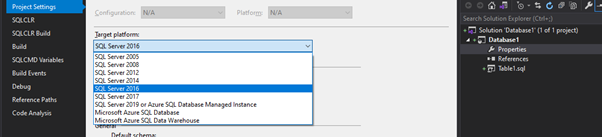
Organize your files #
This is not a requirement, but I find it easier to navigate and develop when I have the same folder structure I am familiar with from Management Studio. If you import a data model from an existing project or SQL source, you can choose what structure Visual Studio should use – I prefer the Schema/Object option.
When creating from scratch, you’ll have to build this into the project yourself. I aim for something like:
Schema name (e.g. dbo)
|- Tables
|- Views
|- Programmability
| Stored procedures
|- Security
| Users
| Roles
| Security Policies
I have seen others have separate folders for fact and dimension tables, too.
Use the designer to create or edit objects #
I’m a big fan of the built-in designer as it saves time searching through docs for valid syntax. To create a new object, right-click on the solution explorer and click Add > New Item. This will bring up a prompt where you can select the object types you wish to add, with some boilerplate code to get you started.
Conclusion #
I’ve talked through the files you can expect to run into when working with SQL Server Data Tools projects, made some recommendations on how to manage these files in your version control repository, and given some best practice for structuring the project and using Visual Studio features to speed up your development.
Please message me on Bluesky if this has been helpful, or useless, or if you have any questions or comments!